The Open Science movement
What is open science?
Open science is an umbrella term covering practices that make research more accessible and reusable:
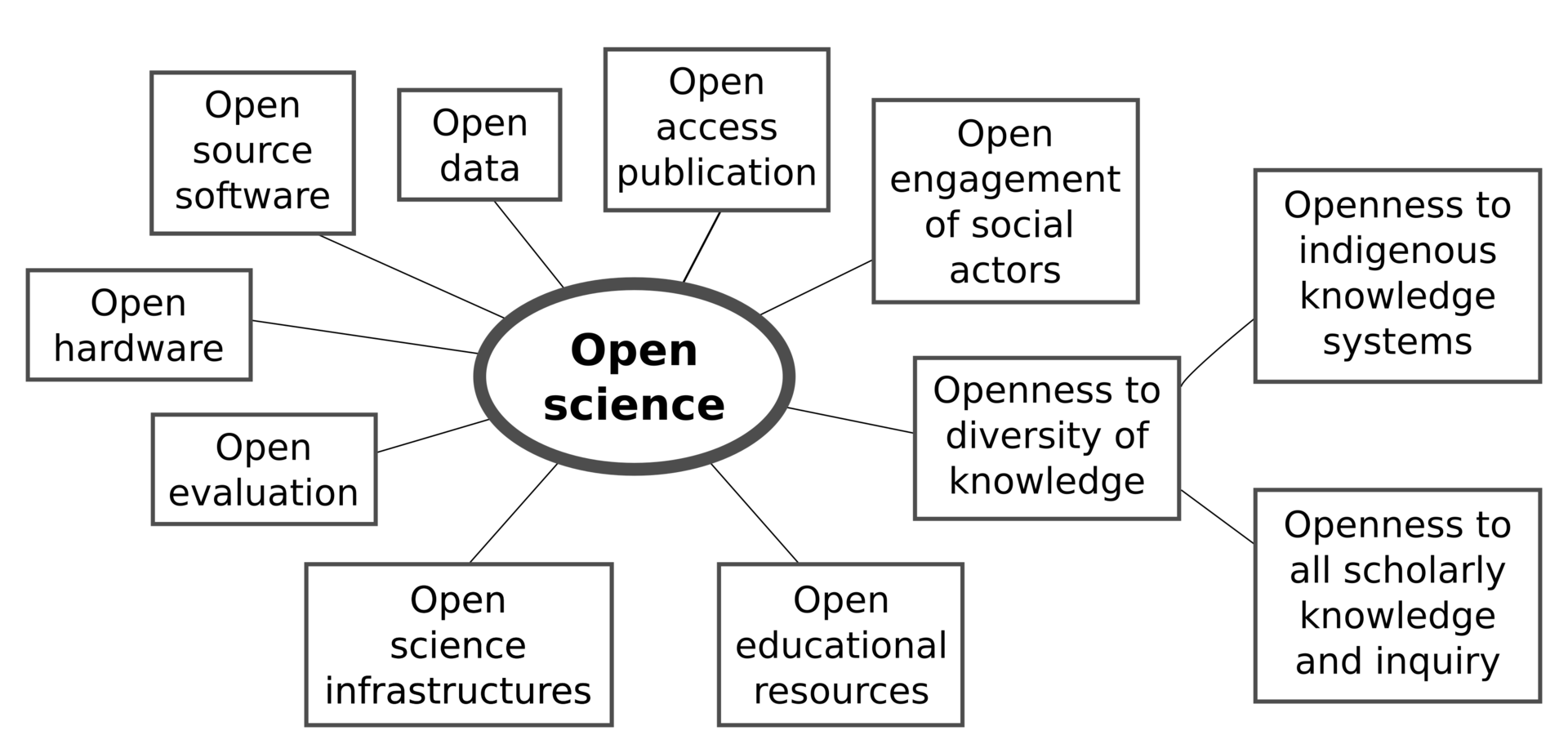
- Open access – making scientific publications freely available.
- Open peer review – making the peer review process and reviewer comments transparent.
- Open data – sharing raw and processed research data for others to inspect and reuse.
- Open code – publishing analysis code, software, or pipelines under open licences.
- Open participation – truly open science invites participation from others.
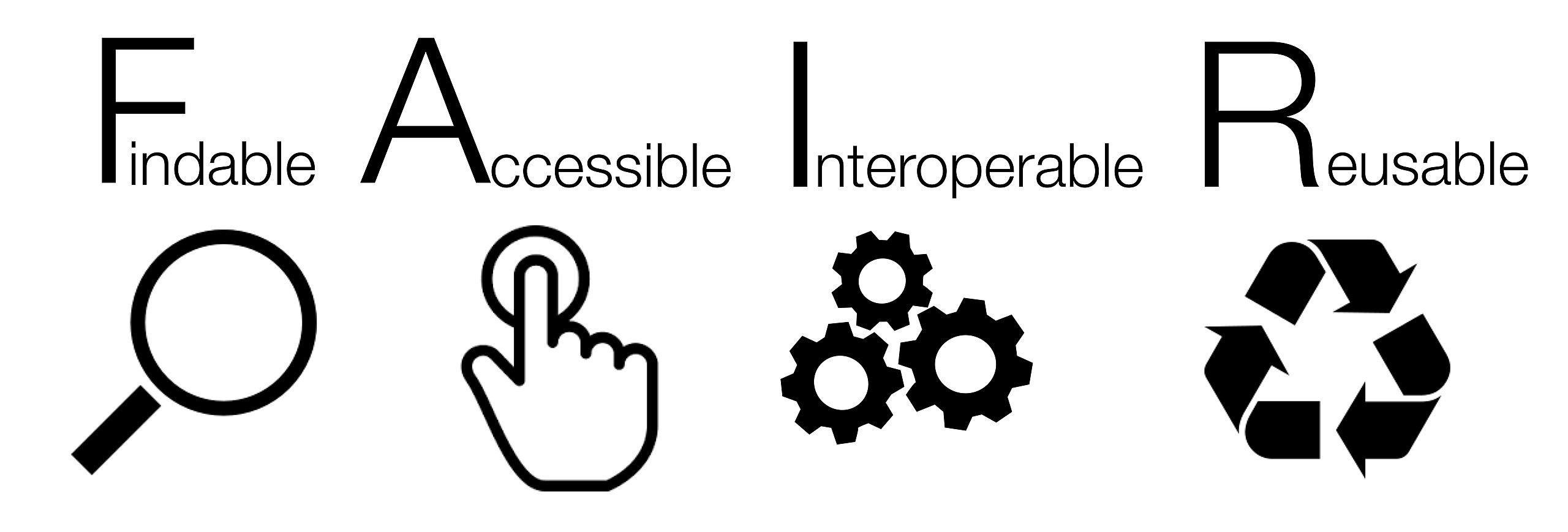
Let’s be FAIR about it
These practices align with the FAIR principles: Findable, Accessible, Interoperable, Reusable.
- Findable: Data and metadata should have a persistent identifier, be rich in metadata, and be registered in a searchable resource.
- Accessible: Data should be retrievable by their identifier, and the necessary protocols for access should be open, free, and universally implementable. Metadata should remain accessible even if the data itself is no longer available.
- Interoperable: Data should use formal, shared, and broadly applicable languages for knowledge representation. Metadata should also include qualified references to other data.
- Reusable: (Meta)data should be richly described with accurate and relevant attributes to enable reuse.
Before starting a project
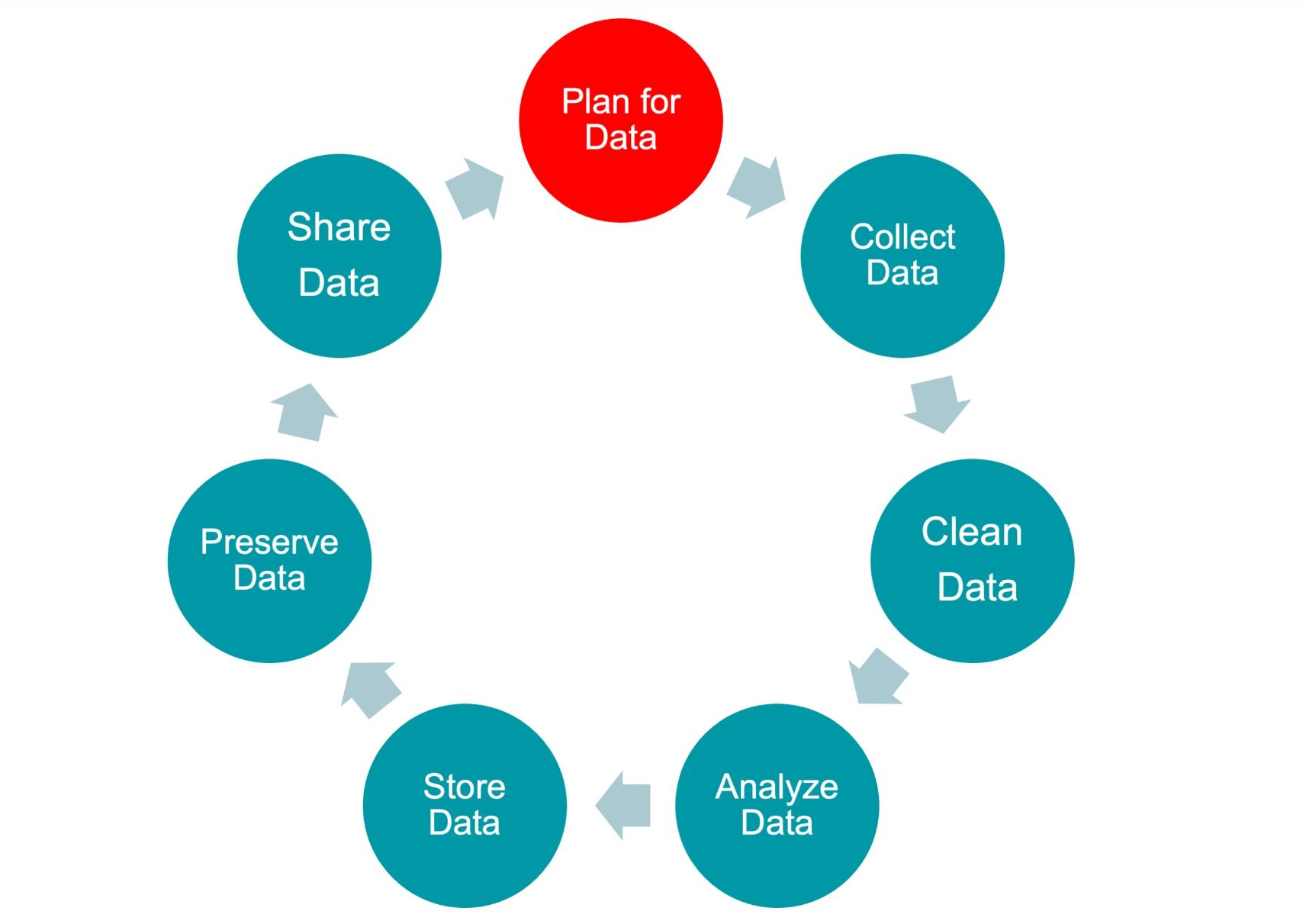
Good open science begins with a plan.
Before collecting any data, researchers can preregister their ideas — writing down what questions they will ask and how they will test them.
This helps show which results were predicted in advance, and which were discovered along the way.
It’s also important to make a data plan: decide how data will be collected, stored safely, and shared later.
Planning early makes it easier to keep the project organised and trustworthy.
The data lifecycle